Deep Convolutional Neural Network
Date : 2022.10.27
*The contents of this book is heavily based on Stanford University’s CS231n course.
[The Deeper We Go]

Everything up to this point sums up into building a deep CNN. The deep version will contain the following properties.
- 3x3 filters for conv layer
- Use He weight initialization
- Use ReLu as activation function
- Use Adam as weight optimization
- Implements dropout
[Deep CNN]
[Train Deep CNN]
The accuracy exceeds 99% which is astonishing if we consider the fact that even humans get more confused with image classification.

[How to Enhance the Network]
Our model reaches an outstanding level of accuracy. It is likely to outperform humans. Our study of CNN was mainly focused on MNIST data. Thus, the model was created to target specific images. However, real world applications must be smart enough to be applied to a more general set of images. Now we should be interested in what affects the general accuracy of networks.
The MNIST data is quite straightforward compared to real world applications. Since the data is single digit numbers, the classification is intuitive for both humans and machines. Thus there is no need to multiple layers, more specifically, the number of layers does not significantly impact the model. Although the topic surrounding whether or not the number of layers affect the outcome remains controversial, there are several upsides to deeper networks.
First, the network relies on a smaller number of parameters (weight/filter). The deeper the layer, the more effective each layer is when it comes to recognizing different features. The conv layer is a good example.
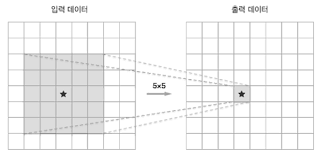
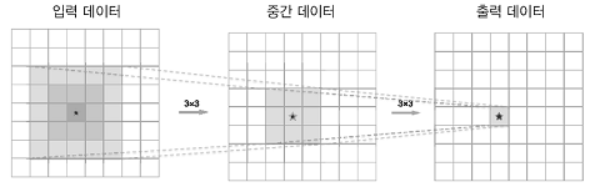
The comparison between the two figures presented shows that multiple layers with smaller filters require less number of individual weight parameters compared to a single big filter. Further, if we use small sized filters, the receptive field gets larger. The receptive field is the area in which neurons are affected. Also, an activation layer follows the conv layer. The more conv layers, the more activation layers. The activation layer consists nonlinear activation functions, and increasing the number of nonlinear functions can improve the network’s ability to capture complex image patterns (features.)
Second, deeper networks are more time efficient because they require less training data compared to simple networks. For example if we want to create a simple model that effectively recognizes images of dogs, the model is more likely to capture unique features of dogs from a wider range of training data. However, if we create a deeper model, the model requires less training data since each layer of the model captures different features. In other words, a deeper model distributes the work amount to each layer, while a simple model has a high work concentration on a single layer.
'Tech Development > Deep Learning (CNN)' 카테고리의 다른 글
| A Recipe for Applying Neural Networks to a Novel Problems (0) | 2022.12.29 |
|---|---|
| CNN: The Afterwork (0) | 2022.12.29 |
| Image Visualization and Primary Networks (feat. LeNet, AlexNet) (0) | 2022.12.25 |
| Completing the CNN (0) | 2022.12.25 |
| Convolutional & Pooling Layers (0) | 2022.12.25 |




댓글