<PyTorch: DataLoaders & Batches>
Date: 2023.05.17
* The PyTorch series will mainly touch on the problem I faced. For actual code, check out my github repository.
[Using DataLoader]
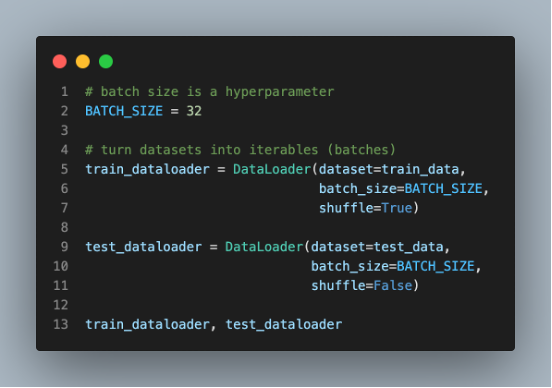
[Why Use DataLoader?]
It serves as an interface between your dataset and the model, allowing you to efficiently load and transform data during the training process.
The main purpose of the DataLoader is to provide a way to iterate over a dataset and retrieve mini-batches of data. It takes a dataset object as input, which could be a custom dataset or one of the predefined datasets provided by PyTorch. The dataset is typically composed of input samples (such as images or text) and their corresponding labels or targets.
The DataLoader class helps in achieving efficient data loading by allowing you to specify various parameters and configurations. Some of the important parameters include the batch size, which determines the number of samples in each mini-batch, and the number of workers, which controls the parallelism for data loading. By using multiple workers, the DataLoader can load and preprocess data in parallel, thereby improving the overall data loading performance.
Furthermore, the DataLoader class provides additional functionalities to enhance the flexibility and usability of the data loading process. For example, it supports shuffling the data at the beginning of each epoch, ensuring that the model sees the data in different orders during training and reducing any bias that may arise from the ordering of the data. It also allows you to specify custom collate functions to control how individual samples are batched together.
During each iteration, the DataLoader returns a mini-batch of data, which is typically a tuple containing the input samples and their corresponding labels. This mini-batch can be directly fed into the machine learning model for training or evaluation. The DataLoader abstracts away the complexities of managing the data loading process, providing a convenient interface that simplifies the training loop implementation.
In summary, the torch.utils.data.DataLoader is a powerful tool for handling data in PyTorch. It enables efficient and parallel data loading, provides options for shuffling and custom data transformations, and simplifies the integration of datasets with machine learning models. By utilizing the DataLoader, you can focus more on designing and training your models, while leaving the data loading and management tasks to this versatile utility class.
[Pros and Cons of Using Batches]
Using batches in neural networks has several advantages:
1. Memory efficiency: Neural networks often require a large amount of data to train effectively. By dividing the entire dataset into smaller batches, the memory requirements are significantly reduced. This is especially beneficial when working with limited memory resources, as it allows models to process data in manageable chunks.
2. Improved generalization: Training a neural network on large batches can lead to better generalization performance. Batch processing introduces a form of regularization called "batch normalization" that helps prevent overfitting. It provides stability to the model by normalizing the inputs within each batch, reducing the sensitivity to the scale and distribution of the individual samples.
3. Faster computation: Modern deep learning frameworks are optimized for batch computations. Utilizing vectorized operations on batches allows for efficient parallel processing on GPUs, which greatly speeds up the training process. The hardware accelerators are designed to handle large matrix computations efficiently, and batching leverages this capability.
4. Noise reduction: By training on batches instead of individual samples, the noise or outliers in any single sample have less impact on the model's parameter updates. This helps to smooth out the training process and improve the stability of the learned representations.
Despite these advantages, there are also some potential drawbacks to consider when using batches:
1. Increased memory consumption: Although batches help with memory efficiency, they still require additional memory compared to processing single samples. The batch size needs to be chosen carefully, considering the available resources. Larger batch sizes consume more memory but can lead to faster computations, while smaller batch sizes require less memory but may result in slower training.
2. Loss of fine-grained information: When training with larger batch sizes, the model receives aggregated information from multiple samples at once. This can result in a loss of fine-grained details that may be present in individual samples. However, this loss of granularity is often acceptable, as the model still learns meaningful representations from the batched data.
3. Possibility of getting stuck in suboptimal solutions: The choice of batch size can impact the convergence behavior of the model. Very large batch sizes can cause the model to converge to suboptimal solutions or get trapped in sharp minima. On the other hand, very small batch sizes may result in slow convergence or difficulty in reaching an optimal solution.
Finding an appropriate batch size requires experimentation and balancing the trade-offs between memory consumption, computational efficiency, and the quality of learned representations. It's important to consider the specific problem, available hardware, and the characteristics of the dataset when determining the batch size for training neural networks.
[Additional DataLoader Features]
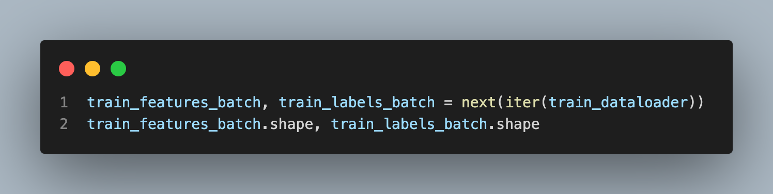
The provided code performs the following steps:
1. It uses the iter() function to convert the train_dataloader object into an iterator, allowing us to retrieve batches of data using the next() function.
2. It retrieves the next batch of data by calling next(iter(train_dataloader)). This statement fetches a single batch from the train_dataloader iterator. The variables train_features_batch and train_labels_batch are assigned to the input features and corresponding labels of the batch, respectively.
3. The output for each train_features_batch.shape and train_labels_batch.shape would be torch.Size([32, 1, 28, 28]), torch.Size([32]) respectively.
The iter() function and the next() function are built-in Python functions, not specific to PyTorch.
The iter() function is used to create an iterator from an iterable object. In this case, train_dataloader is an iterable object, typically a PyTorch DataLoader that provides batches of data during training. Calling iter(train_dataloader) creates an iterator object that can be used to access elements of train_dataloader sequentially.
The next() function is used to retrieve the next element from an iterator. By calling next(iter(train_dataloader)), you obtain the next batch of data from the train_dataloader. This is often used in a loop to iterate through the batches of data during training or testing.
In summary, this code sets up a data loader for the train_data dataset, where each batch will contain 32 samples. It then retrieves the first batch of data and assigns the input features and labels of that batch to the variables train_features_batch and train_labels_batch, respectively. This allows you to process the data in mini-batches during training, which is a common practice in machine learning to improve efficiency and generalization performance.
'Tech Development > Computer Vision (PyTorch)' 카테고리의 다른 글
| PyTorch: The End (0) | 2023.07.08 |
|---|---|
| PyTorch: Review of Conv Layer & Pooling Layer (0) | 2023.07.08 |
| PyTorch: Classification Metrics (0) | 2023.05.18 |
| PyTorch: Results & Trouble Shooting (0) | 2023.05.15 |
| PyTorch: Multiclass Classification Model (0) | 2023.05.15 |




댓글